AB testing and Product Learning Notes
Task Lists
- Introduction and the Motivation
- Running and Analyzing Experiment: An end to end example
- Experiment trustworthiness
- Organizational Metrics
Based on the book Trustworthy Online controlled experiments
Introduction and Motivation
Online controlled experiment(A/B testing)
The most common online experiment setting
-
Users are randomly split between variants in a persistent manner. It has two groups in the simplest version: Treatment B and Control A.
-
Overall Evaluation Criterion(OEC) quantitive measure of the experiment’s objective, e.g. DAU, LTV, session per user(usage), relevance(time to success). The requirement for OEC:
- Measurable in the short term
- Causally drive long-term strategic objective
Metric teams: choosing metrics, validating metrics and evolving metric over time
Motivation
Case desciption:
- Increase the user churn rate in a subscription business, e.g. Amazon Prime, Spotify memebership. To achieve this we may need to introduce a new feature and prove there is causal relationship between the new feature and the user churn rate. causal inference related knowledge might required in this process. A thing we need to remember is Correlation doesn’t imply causality.
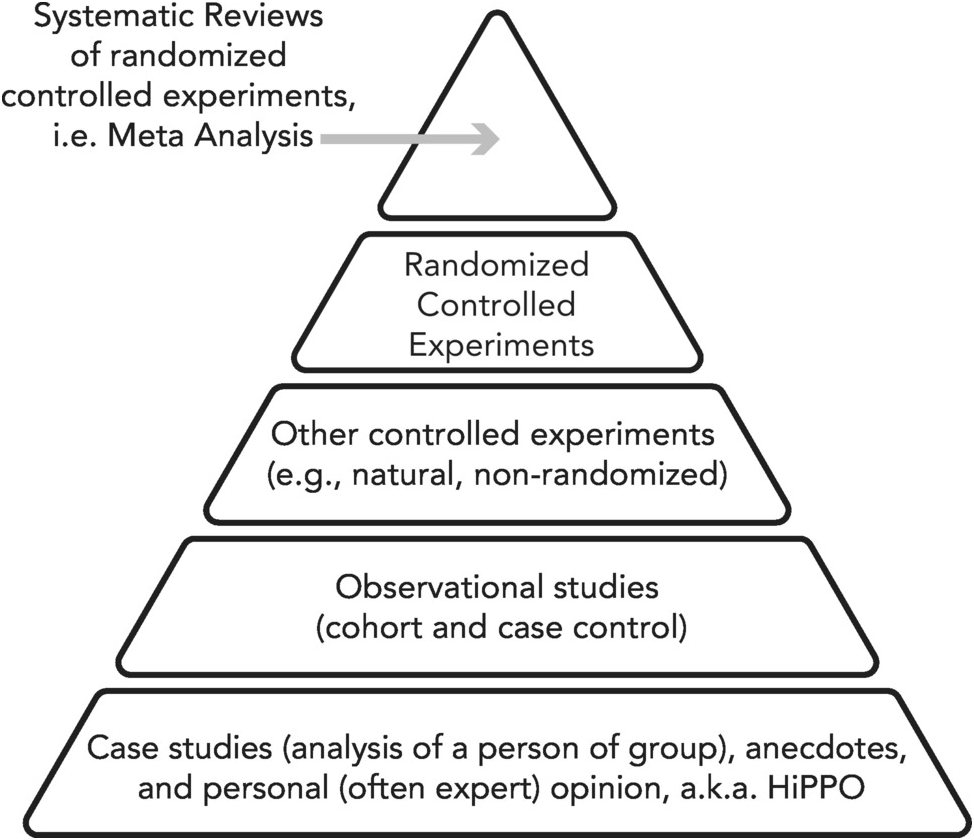
Motivation:
- Establish causality with high probability
- Detect minor and unexpected changes
Experiment Trustworthiness
Extreme results
- potential explanations
- instrumentation(logging)
- computational error
- loss of data
Misinterpretation of the result
- Common errors
- Lack of power
- P-values interpretation: the level of marginal significance within a statistical hypothesis test representing the probability of the occurrence of a given event.
Multiple Comparisons
- Common senarios
- Multiple metrics
- P-values over time
- Population segementation
- multiple iterations
Confidential Interval
quantify the degree of uncertainty in the treatment effect
Interpretation of CI: how often the CI computed from many studies would contain the true treatment effect.
Internal Validity
- SUTVA – no interection
- exmaple of violations: social networks;communication tools; collaboration tools; shared documentation; two-sided market(ebay/uber/lyft)
- Intention to Treat
- Survivorship Bias
- Sample Ratio Mismatch(SRM)
- Browser redirect
- Lossy instrumentation
- Residual or carryover effect
External Validity(Generalization)
Primary Effect and Novelty effect
- highlight by take the new users
Segementation
- Market/Country
- Device/Platform
- Time of Day/Day of Week
- User Type(new/existing/returning)
- Single/Shared/Family
Conditional Average Treatment Effect in causal inference
Simpson Paradox
- Possible reasons:
- Different Treatment/Control Assignment in different segementation.
- Sampled not uniform
Organizational Metrics
Goal Metrics (Sucess Metrics)
May not be easy to move in the short term since each intiative may only have a very small impact on the metric or impacts take a long time to materialize.
Goal metrics should have the characteristic:
- Simple
- Stable.
Driver Metrics (Sign post Metric)
Shorter-term, fast-moving, more sensitive
- HEART Happiness, Engagement, Adoption, Rentention and Task Success
- AARRR! Acqusition, Activation, Retention, Referral, Revenue
Driver metrics should have the characteristics:
- Aligned with the goal: driver of sucess
- Actionable and relevant
- Sensitive
- Resistant to gaming
Guardrail Metrics
guard against violated assumptions, latency
- HTML response size per page
- JS error per page
- Pageviews per user
- Client crash
Other taxonomies
-
Asset & Engagement
- Accumulation of static assets, total number of Facebook users/ total number of connection
- The value a user receives as a result of an action/ by others using the product, session/pageview
-
Business & Operational
- Track the health of business, Revenue per user/DAU
- Track operational concerns, Queries per second
we need to measure goal, driver, and guardrials at both company level and team level.
Aligning goal and driver metrics to overal business strategy
An increasing in latency of even a few milliseconds can result in revenue loss and a reuduction in user statisfaction.
Unconstrained metrics are gameable
Evaludating Metrics
Establishing the causal relationship of driver metrics to organizational goal
Running and Analyzing the experiment
Case study
-
Objective marketing departments want to increase sales by sending coupon codes/ promotion code for discount. by simply adding a coupon field at the check out page. We need to evaluate the effect of changing UI. Access the feasibility of the new business model.
-
Concerns The newly added field would distract people from checking out, further leads to revenue decreasing.
-
Approaches Fake door/ painted door approaches.
-
Goal Metrics Revenue per user; randomization unit is user
- Users included The users who start the purchasing process
- Not all users: noisy since most of the users won’t even start the process
- Not the users who complete purchase:
- Hypothesis Testing
- baseline mean(for most metrics) and standard error
- experiment size/randomized units/how long to run
- statistical significance and practical significance
- How long to run the experiment
- More users need to be included – to increase the statistical power.
- Day-of-week effect – capture the weekly cycle– experiment longer than 1 week
- Seasonality – e.g holidays
- Primacy and novelty effects experiments take time to stablize
Before interpret the result, we might need to have a sanity check
Results to decisions
- Case one: no statistical significance and practical significance and the CI is not very wide or small. Reiterate/abandon the idea.
- Case two: both statistically significant and practical significance. Launch
- Case three: have statistical significance but not practical significance Discuss whether it worths it.
-
Case four: Confidence Interval is very wide, Include more units gain more power.
- Case 5: practical significant and not statistical significant repeat the experiment.